-
Terraform의 첫 번째 함정: 코드 읽을 때주제탐구/인프라 2019. 9. 2. 10:39
이 글은 Terraform의 4가지 함정이라는 시리즈의 일부로 작성하고 있다.
- 인트로: 인프라 자동화, 쓰면 좋습니까?
- 첫 번째 함정: 코드 읽을 때
- 두 번째 함정: 코드 수정할 때
- 세 번째 함정: 코드 적용할 때
- 네 번째 함정: AWS 특수 함정
Terraform 코드 첫인상
우리 팀은 인프라 자동화에 테라폼을 많이 활용하고 있다.
EC2 몇 대 올리는 간단한 리소스부터, AWS 서비스랑 얼기설기 얽히는 복잡한 리소스까지
서비스에 직접적으로 사용되는 많은 리소스에 테라폼을 쓰고 있다.
그런데 사실 우리 팀에는 몇 주 전만 해도 테라폼을 아는 개발자가 거의 없었다.
전능하신 한 팀원분에 의해 테라폼 코드가 존재하게 되었고,
서버 개발자들도 인프라 작업을 하기 위해서 테라폼을 배워야 하는 상황이 되었다.
전능하신 분께서 테라폼 쉽다는 거 다 거짓말이라는 말씀을 여러 번 해 주셔서,
"그래도 사람이 쓰는 건데 얼마나 어렵겠어~"
하고 인프라 관련 repo에 들어갔는데 말씀대로 어려워서 놀랐던 적이 있다.
어디가 진입점이지?

대충 이런 느낌? 처음 본 테라폼 모듈은 대충 이런 느낌이었다.
(코드는 여기에서 볼 수 있다!)
cloudwatch.tf랑 sqs.tf는 뭐 "이름이랑 관련된 게 있겠구나~" 싶었지만,
문제는 코드의 진입점이 어디인지를 가늠할 수가 없었다는 것이었다.
그래도 이름값이 있는데 main.tf 아닐까? 생각하고 들어가면,

이런 코드 몇 줄밖에 없었다. aws, ap-northeast-2는 이미 아는 단어들인데,
provider, locals 같은 생소한 단어들과 엮어 있으니 의미를 알기 어려웠다.
var.tags는 내가 아는 그 var가 맞나 싶었고.
다른 파일을 둘러보아도 비슷했다. variables.tf에 가면,

variable이라는 게 있다. 이건 변수인 듯했고,
outputs.tf라는 데 가면...

output이라는 게 있다. 이건 반환값인가? 그러면 데이터가 어디로 들어오는 거지?
하지만 테라폼 코드 중에서 가장 압권인 건...

data였다. 이런 제너럴한 이름으로? 이렇게 많은 데이터가?
멘붕전반적으로 평소 접해 오는 코드의 체계와 엄청 다르다는 느낌을 받았다.
locals, variable, output, data가 어떻게 변별되는지 쓰임새만으로는 알 수가 없었고,
코드를 수정하려면 무엇을 추가해야 하는지 알아야 하는데, 그걸 모르니 턱 막혔던 것 같다.
이런 코드의 생소함이 테라폼의 첫 번째 함정인 것 같다.
알고 있는 단어의 쓰임새가 평소 코드와 다르게 쓰여 혼란했고,
데이터가 어디서 들어와서 어디로 나가는지 바로 파악하지 못했다.
심지어 어떻게 인프라를 생성한다는 건지도 모르겠어!!

이번 주 안에 테라포밍하기로 했는데!!! 그날 퇴근하고 나서 <테라폼 설치에서 운영까지>를 죽 읽어나갔고 많은 것을 알 수 있었다.
실행 방법
우선 이 코드 더미들로 어떻게 인프라를 생성하는 건지 알아야 했다.
그래야 플로우가 보이고, 정보가 들어오는 곳과 나가는 곳을 알 수 있으니까!
아까 본 그 코드 더미들 테라폼 코드들은 하나의 폴더 단위로 묶여 있고, 필요할 때 이를 모듈로 사용할 수 있다.
CLI상에서 이 폴더에 들어와서 terraform apply를 날리면,
terraform이 해당 depth 안의 모든 파일을 읽어내고, 리소스 간의 연관 관계를 분석하여
인프라를 생성/변경/삭제하기 위한 계획을 만든다.
그렇기 때문에 해당 depth 안이라면 원하는 코드 블럭을 어느 파일에 배치해도 상관없다.
즉 자신이 원하는 대로 파일을 쪼갤 수 있다.
우리 팀은 variable과 output은 각각 하나의 파일에 모으고,
resource의 경우 특정 AWS 서비스와의 관련성을 기준으로 묶어 두었다.
이 점을 생각하고 하나하나씩 파헤쳐 보자.
output
output은 가장 쉽다. 테라폼 모듈이 실행되고 나서 출력/저장하고 싶은 값을 명시하는 부분이다.
가령 위 모듈을 가지고 CLI에서 terraform apply 명령을 날리면, 이런 출력을 볼 수 있다.

코드의 적용 결과를 출력하고,
명시해 두었던 output값들을 Outputs: 아래에 예쁘게 출력해 준다.
이 값들을 가지고 실제 애플리케이션의 설정 파일(yaml 등)에 넣거나,
Jenkins Job 변수로 넣어서 애플리케이션을 돌릴 수 있을 것이다.
일일이 AWS 콘솔에 들어가서 원하는 값을 긁어오지 않아도 되어 편하다.
그렇다면 저장은 어디에 하는가?
terraform apply를 하고 나면 해당 코드의 적용 결과가 .tfstate 파일에 저장되는데,
여기에 output도 함께 저장된다.
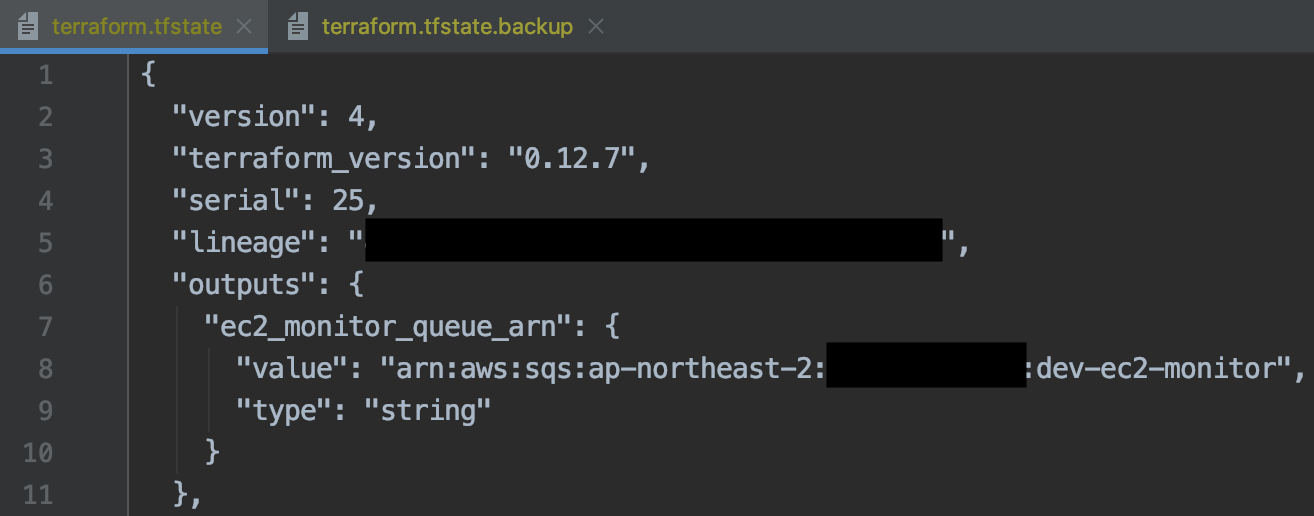
이 state 파일은 나중에 다시 설명할 기회가 있겠지만, 여러 사람이 수정하는 것을 막기 위해서
AWS S3같은 원격 저장소에 저장해 두고 사용 시 Lock을 걸어버리기도 하는데,
이를 remote state라고 한다. (자세한 내용은 다다음 글에서 다룰 예정)
다른 모듈의 remote state가 이미 원격 저장소에 저장된 경우 그 모듈의 output 값을 끌어다 쓸 수 있다.
이런 방식으로 분리된 모듈 사이에서 정보를 공유할 수 있다.
무튼 output은 이름 그대로 저장/출력되는 값이라는 걸 알 수 있다.
variable
variable은 인프라 생성 전에 입력받는 값이다.
모듈 안에서는 var.tags, var.environment같은 형식으로 사용한다.

이 값을 입력할 수 있는 시점은 다양하다.
가령 이 모듈을 CLI에서 적용하려고 하는데, 기본값이 없는 variable이 있다면...

tags는 기본값이 있어서 물어보지 않는다. 이렇게 적용 전에 인터랙티브하게 물어봐준다.
이게 싫다면 CLI 명령에 파라미터로 넣을 수도 있고,
.tfvars 파일에 넣어 전달할 수도 있고, 환경 변수로 넣어둘 수도 있다.
하지만 보통 테라폼 모듈은 개발 환경과 운영 환경을 구분하여 재사용하기 때문에,
이렇게 모듈을 사용할 때 variable값을 넘겨주는 때가 많다.

개발 환경 예시 위 코드는 개발 환경에서 모듈을 사용하는 예시로,
environment와 tags 두 개의 변수에 dev 환경을 나타내는 값을 입력하는 것을 볼 수 있다.
만약 운영 환경에서 이 모듈을 사용하고 싶으면, 운영 환경쪽 폴더에...

운영 환경 예시 variable 값만 바꾼 파일을 넣어주면 된다.
이런 방식으로 여러 환경에 동일한 인프라를 생성할 수 있다.
locals
가장 처음에 봤던 main.tf, 여기에는 locals라는 게 있었다.
locals는 모듈 내에서 여러 번 재사용할 값을 담는다.
마치 지역 변수의 느낌인데, 폴더 하나를 scope으로 가진다.
모듈 안에서 여러 개의 resource에 공통 네이밍 규칙을 적용하고 싶을 때 등등
다양한 상황에서 지역 변수처럼 요긴하게 활용할 수 있다.
가령 위처럼 locals에 모듈 공통 태그를 지정하면,

CloudWatch에서도,

SQS에서도 쓸 수 있다.
사내에 AWS 리소스의 태그 규칙 같은 게 있다면, 이렇게 관리하면 무척 간편해진다.
무튼 모듈 안에서 재사용할 값은 이 locals를 사용해 정의한다.
data
앞서도 말했지만, 개인적으로 data가 테라폼에서 가장 애매한 것 같다.
이렇게 general한 이름으로 이렇게 많은 데이터를...?
어마어마하다 data는 Data Source, 즉 정보를 가져오는 곳을 정의한다.
그리고 data가 읽을 수 있는 정보의 출처는 매우 다양하다.
provider(가령 AWS)에서 나왔을 수도 있고
내가 입력한 값을 가공해서 나왔을 수도 있고
remote state를 읽어서 나왔을 수도 있다.
정말 다양한 곳에 있는 다양한 정보를 이 data로 끌어올 수 있다.
몇 가지 예시를 보면 바로
얼마나 general한지알 수 있다.
가령 aws_availability_zones는 provider를 제공할 때의 region 정보를 기반으로 가용 영역의 리스트를 가져온다.
즉 provider(여기서는 AWS)에 접속하여 정보를 가져오는 data 중 하나다.

반면 aws_arn은, 입력한 ARN을 파싱하는 역할을 한다. (ARN은 AWS 리소스의 고유 식별자를 말한다)
즉 사용자가 입력한 값을 가공하는 data 중 하나다.
(가령 위의 ARN에서 Account ID인 123456789012만 가져오고 싶다면
data.aws_arn.db_instance.acccount로 참조할 수 있다.)
이렇듯 외부에서 끌어오는 정보가 아니라, 내가 입력한 정보를 가공하는 경우에도 data를 사용할 때가 있다.

그리고 terraform_remote_state처럼 외부 정보이지만 provider가 아닌 다른 곳에서 끌어오는 경우도 있다.
좀 전에 output을 설명하면서 원격 저장소에 output 값을 remote state로 저장하고
다른 모듈에서 끌어다 쓸 수 있다고 했는데, 이때 끌어오는 역할을 해 주는 게 terraform_remote_state다.
remote state는 다양한 곳에 저장할 수 있는데, 여기서는 AWS S3 버킷에 저장하고 끌어다 쓰고 있다.
아까 저장한 ec2_monitor_queue_arn이 사용되는 것도 볼 수 있다 :)
그렇다면 아까 만났던 aws_iam_policy_document는
위 셋 중
굳이 따지자면어느 것과 비슷할까?
문서를 읽어보면 이 data의 존재 의의는 유저가 입력한 값을 바탕으로
JSON을 만들어내는 데 있다는 것을 알 수 있다.
그래서 사용할 때도 json이라는 attribute 딱 하나만 사용한다.

즉 사용자가 이렇게 저렇게 입력한 값을 JSON으로 가공하는 역할을 하므로
aws_arn과 가장 비슷한... 것 같다.
개인적으로처음 테라폼 코드를 접하면서 가장 혼란을 줬던 부분이 data의 출처가 매우 다양하다는 것이었는데,
이런
갑툭튀data에만 익숙해져도 코드가 훨씬 쉽게 이해될 거라는 생각이 든다.나머지는 문서에
좀 전에 다뤘던 output, variable, locals, data 이 네 가지 외에는
거의 resource인 경우가 많다. 우리 팀 코드가 그렇다.
그리고 resource는 문서를 보면서 사용법 익히면 된다.
손에 익을 수는 있어도, 절대 외워서 작성하는 종류의 코드가 아니다...!

왜냐면 이렇게나 많은 provider가 있기 때문에...! 필요한 인프라 리소스가 있을 때 문서를 찾아보면
ECR, DynamoDB, IAM, RDS, S3, SQS...
정말 많은 것들이 준비되어 있다는 것을 알 수 있다.
예시를 가져다 쓰고, 파라미터를 조금 바꾸는 식으로 작성해도
꽤 복잡한 인프라 구성을 만들어 낼 수 있다.
만약 원하는 게 없다면... 투표하고 기다리면 된다.
Go 잘하면 직접 만들어 PR
...라고 생각했지만, 복잡한 인프라를 설계하다 보면 만나게 되는 문제가 하나 있다.

두둥 다음 글에서는 Cycle을 해결하는 방법을 비롯해서,
테라폼 코드를 작성할 때 만나는 함정들을 다뤄 보려고 한다.
'주제탐구 > 인프라' 카테고리의 다른 글
인프라의 코드화: 쓰면 좋습니까? (0) 2019.08.26